SmartOS
SmartOS is Joyent’s open source hypervisor built on top of Illumos (Solaris). It supports QEMU/KVM & Zones for virtualization, and includes ZFS, Crossbow, & DTrace. Zones are to SmartOS/Solaris like OpenVZ Containers are to Proxmox, except Solaris has done it a lot longer & you could say it’s more proven. With SmartOS, Joyent has taken a modern approach to it’s binaries, using GNU tools by default (albeit not a true GNU platform). IMO that’s a welcome departure away from Solaris’ Unix roots.
I didn’t grok SmartOS right away. I’m used to installing a type 1 hypervisor on a server’s local drive, but SmartOS is a hybrid of that. It’s primary OS is read-only, & runs from a USB key, CD-ROM, or via PXE boot image over network. When you boot it on a machine, it checks for a ZFS pool called “zones” that’s configured for SmartOS. If it doesn’t see that, it goes through a setup process to create the pool for you. The zones pool contains the configuration specific to the hypervisor itself, as well as storage for the zones/vm’s themselves. Oh yeah, and there’s no GUI (at least not by default)… everything’s configured on the command line. So you can’t just setup a hypervisor quickly by clicking through an installer, you gotta learn how to do it. Luckily the SmartOS Wiki is well written & anyone with some basic command line experience can figure it out.
Install
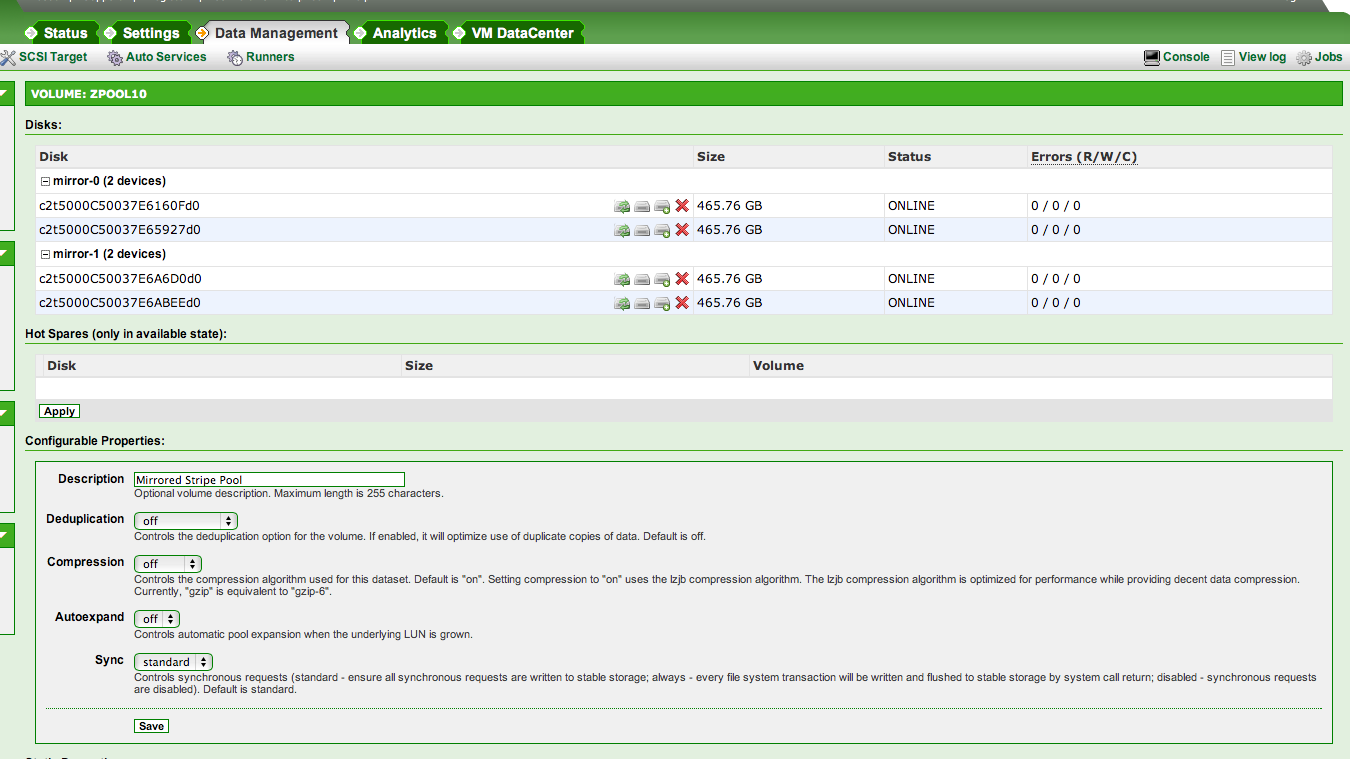
One thing I didn’t like about the installer is it doesn’t really give you a way to specify the layout of your disks for the zones pool. If you have 4 disks & you select them all, it’ll create a raidz1 pool. Eh, no thanks. What I did was select only two disks so it’d create a mirror, then after the OS was running I created another mirror with the other two disks & striped the two mirrors.
Network
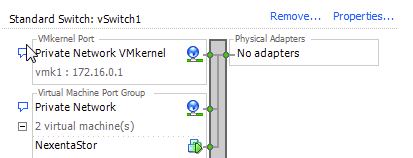
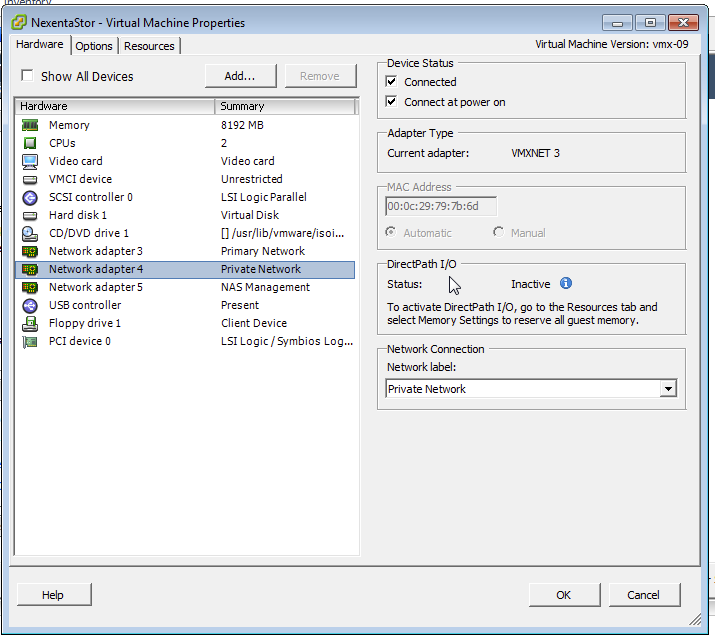
With Crossbow, I was able to set up 2 link aggregate for my VMs to use, and kept the primary interface for admin stuff only. Overkill for a homelab, but why not if my switch supports it? :) The wiki link above describes how to do that. SmartOS applies “tags” to the interfaces, & you can specify to the VM which tag to use. I also found out you can create a “virtual switch” with Crossbow called an etherstub to allow VMs to communicate to each other on a private network.
Virtualization
Setting up the VMs/Zones themselves is pretty easy once you understand it. You can pull in preconfigured images from Joyent’s repositories via imgadm, or you can install via ISO. The configuration of the VM/Zone is done via a JSON payload file, & there’s even a website to create the config files for you. Remote access to the VM’s console is easily done via VNC or ssh’ing to the host & using zlogin to the zone itself. I’m very glad tab autocomplete works with the UUID’s of the VMs/Zones because those would be a bear to type or copy/paste repeatedly.
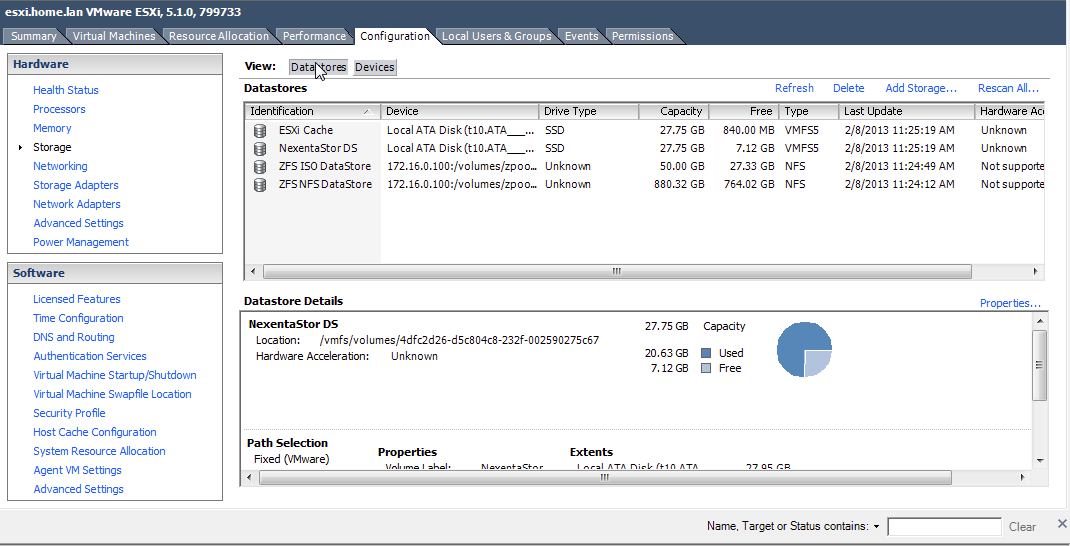
Storage
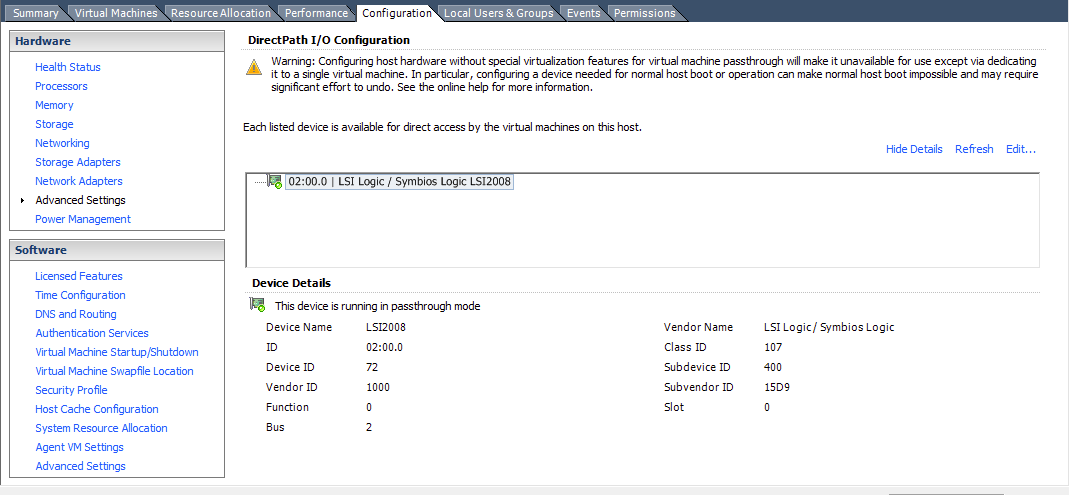
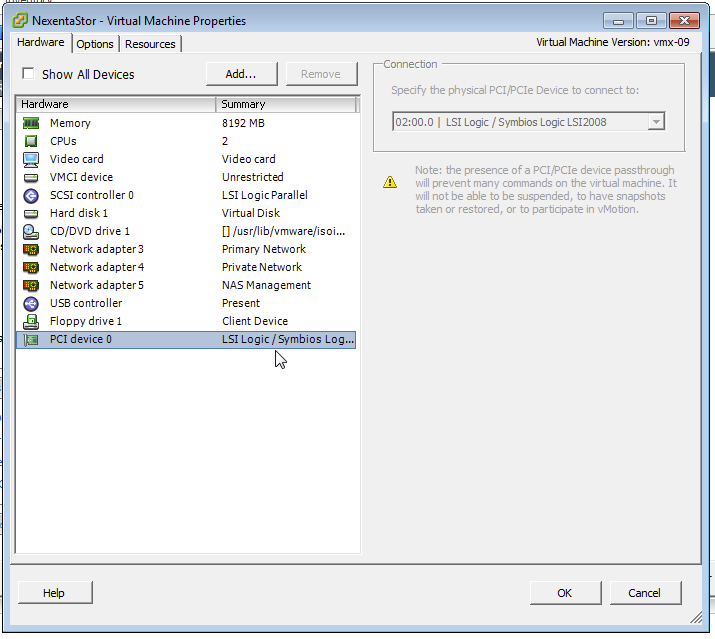
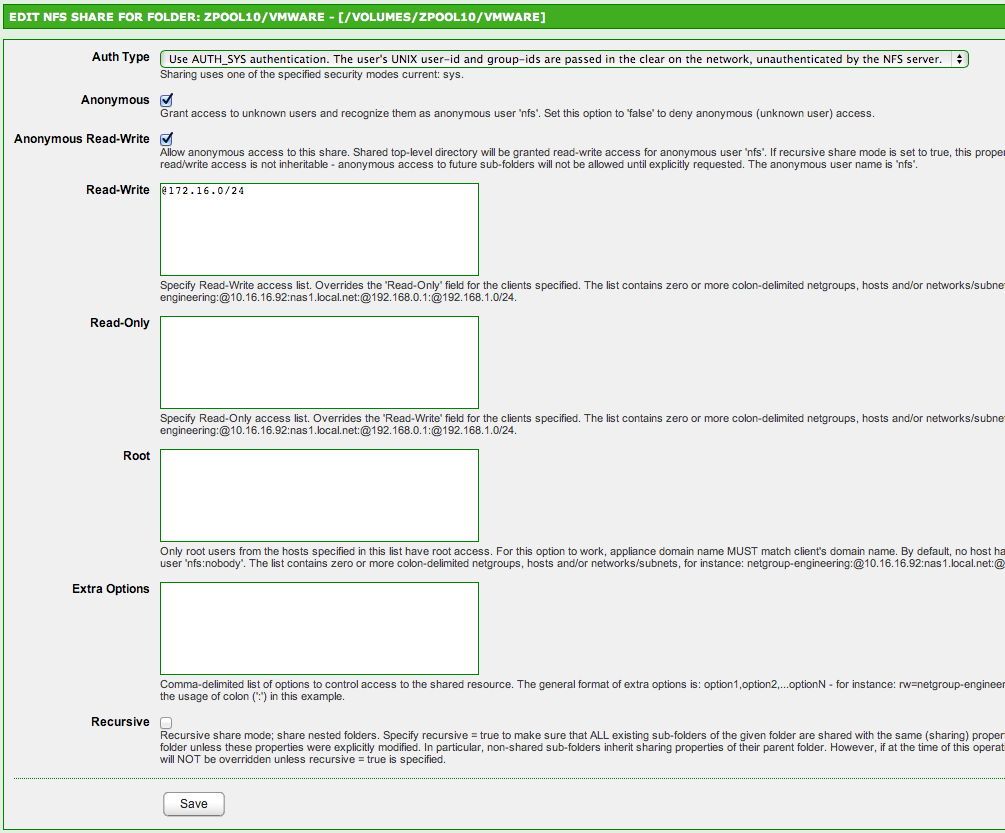
One of the first things I needed to do once the hypervisor itself was up & running was replace the storage server part missing from my previous all-in-one setups. This is a bit different because I don’t need to pass through anything… SmartOS is managing it’s own storage for it’s VMs/Zones & it’s faster too (obviously). I have another pool for data storage & backups, but I can’t use SmartOS’s global zone to manage it since it’s read only for the most part. So, I created a non-global zone for managing the storage pool itself, as well as to have a place to install the software I wanted such as Netatalk & Crashplan. For Netatalk, I compiled myself by loosely following this guide & Crashplan installed without a hitch using pkg.
The key was passing the tank zpool to the zone so it could be managed there. This is done easily with zonecfg:
1 2 3 4 5 6 7 8 9 | |
I didn’t use the LOFS method mentioned in the above Netatalk guide because I’m not familiar with it. zonecfg is the way I’ve always done it & seems to work fine here.
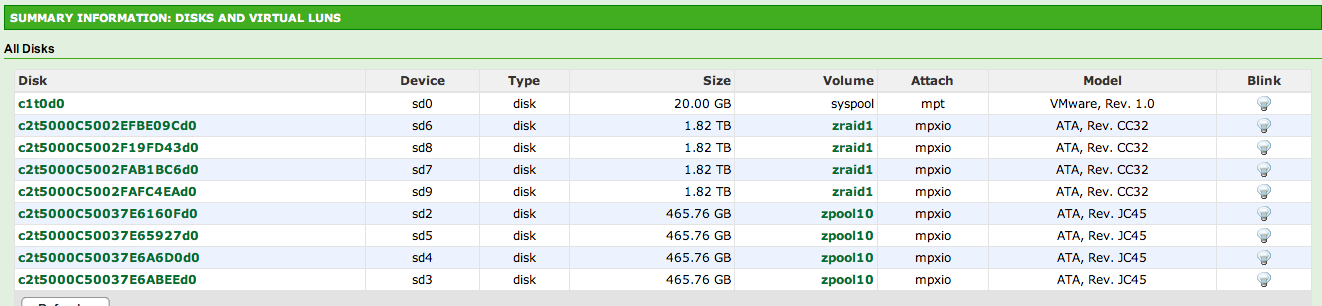
Just to be clear, here’s my storage pool layouts:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | |
GUI
As mentioned earlier, there’s no GUI in SmartOS by default. Joyent sells SmartDatacenter & there’s also a 3rd party OSS tool called Project FiFo. FiFo is an excellent project, and I have it running in a zone. However, I find myself going back to the command line more for better flexibility. I don’t particularly like how FiFo handles networking, I don’t like how it measures utilization by what you’ve committed to the VMs/Zones rather than what’s actually being used, and each component has it’s own couchdb beam.smp process that can eat up resources. I do like it’s graphing per VM/Zone as well as the browser based console to the VM/Zone itself, and the ease at which I can deploy an image. It also taught me that I can attach my ssh key to any VM/Zone for easier access, which is very cool.
Monitoring
FiFo does some decent monitoring, but I’m also using New Relic, which I was surprised to see supports SmartOS. You can get a free New Relic account that’ll retain data for 24 hours. Perfect for me:

There’s also DTrace which is supposedly the best stats tool ever, but I have no clue how to use it short of finding other people’s scripts such as Brendan Gregg’s (which look awesome) but even then most of the time I have very little idea what it’s telling me. Something I can improve on for sure.
Automating
This is one of the areas that requires extra work on your part. The nice thing about using a product like FreeNAS or NexentaStor is that automating things is easier via the built in management tools. If I want to automate something in SmartOS, I have to script it myself (at least from what I can tell). Though, I have dropped several hints to the FiFO guys that if they branch out to a ZFS Filer type project, they’d become very popular IMO.
One of these areas that you have to figure out is ZFS snapshots, but I found a great project on Github written in NodeJS called zsnapper & it works a treat.
Links
Some useful links (in no particular order):
- http://wiki.smartos.org/display/DOC/SmartOS+Users+Guide
- http://blog.smartcore.net.au/
- https://github.com/calmh/zsnapper
- http://project-fifo.net
- smartos & project-fifo channels on Freenode